随着大模型能力一路狂飙,各路测评基准也遍地开花。
从经典的MMLU、HellaSwag,到多模态方向的MMMU、MathVista,再到AGI风格的Arena对决、Agent任务、Tool-use测试。
如何科学地衡量LLM在长时、复杂、真实世界任务中的能力,至关重要。
今年3月,METR发布重磅研究《Measuring AIAbility to Complete Long Tasks》,首次提出令人眼前一亮的新指标:
50%任务完成时间视野(50%-task-completion time horizon)
——也就是:AI能以50%成功率完成的任务,人类通常需要花多久?

论文链接:https://arxiv.org/pdf/2503.14499
据此,METR展开了一系列研究,包括任务复杂度设定、人类基准时间测量、多模型对比实验到层层统计回归建模。
最终,团队精准量化了AI智力演进速度,并抛出惊人预测:
按照目前增长速度,5年之后,大模型可能就能在一天内自动完成原本需要人类数月才能完成的复杂任务。
别眨眼,LLM每7个月实力翻倍!
METR团队选出每一时间段的最强模型,建立了一个精确的「大事年表」,进一步定量分析模型能力随时间的增长情况。
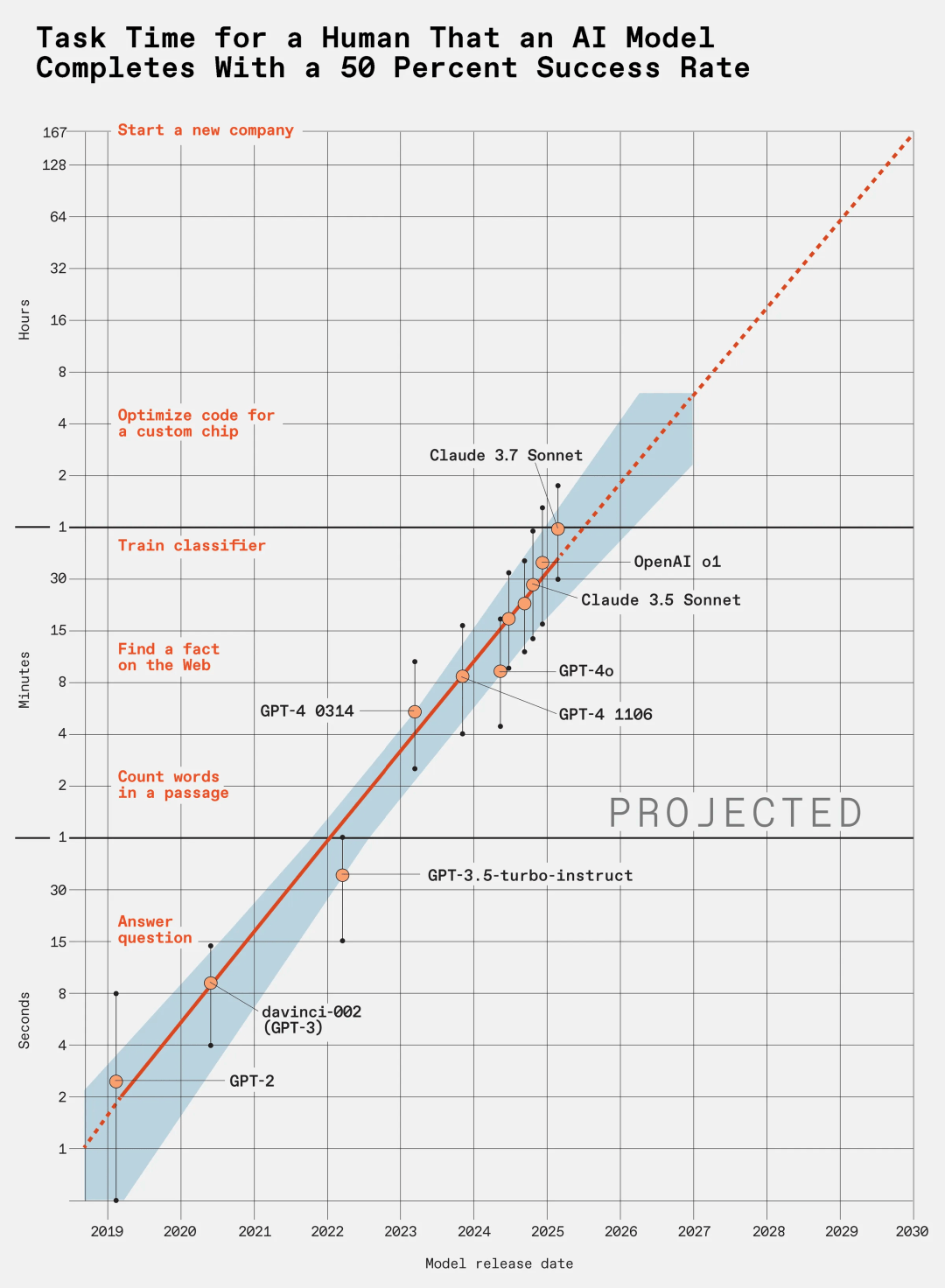
结果显示出清晰的指数增长趋势:在过去的六年中,模型能力每7个月翻一番。
图中的阴影区域表示通过在任务家族、任务以及任务尝试之间进行分层自助法(hierarchical bootstrap),计算得出95%的置信区间。
不过,这个指数增长趋势非常陡峭,所以于对误差有很高的容忍度。
即便绝对测量误差达到10倍,能力到来的时间也仅会改变大约2年左右。
因此,团队对不同能力何时出现的预测基本不会出错。
模型vs人类:用「人类耗时」测量大模型智力
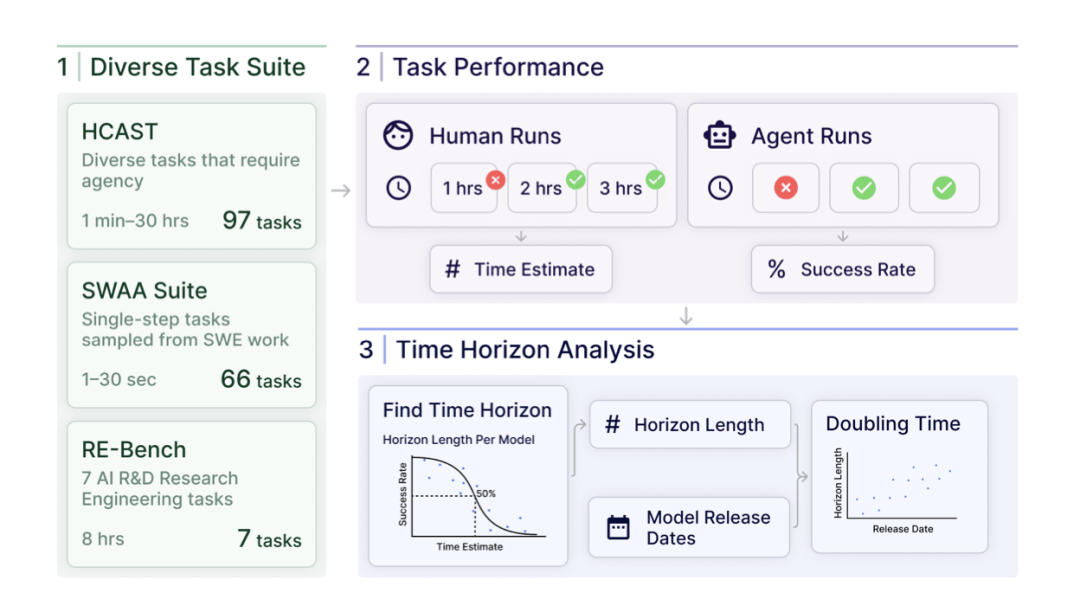
METR这项研究的核心就是他们提出的这项指标:「任务完成时间视野」(task-completion time horizon)。
这个指标相当于给分别完成任务的人和AI加了个映射:
想象一组各不相同的任务,人类完成这些任务分别需要不同的时间。
把这些任务交给AI模型去做,然后找出AI能以50%成功率完成的那一档任务(但不考虑AI用的时间)。
然后对应去看人类完成这一档任务通常需要多长时间。
这个人类所需的时间,就是该模型的50%-task-completion time horizon,也即「任务完成时间视野」。
为了证明这个基准的有效性,METR团队做了翔实的统计分析。
结果显示,人类基线完成某项任务所需时间,与各模型在该任务上的平均成功率之间存在负相关关系。
简而言之,人做起来越慢,模型做起来越容易失败。
并且,用指数模型拟合这个负相关趋势效果很好。
用模型成功率对人类完成时间的对数做回归分析,算出的R²约为0.83,相关系数为0.91,这比不同模型之间平均成功率的相关系数还高。
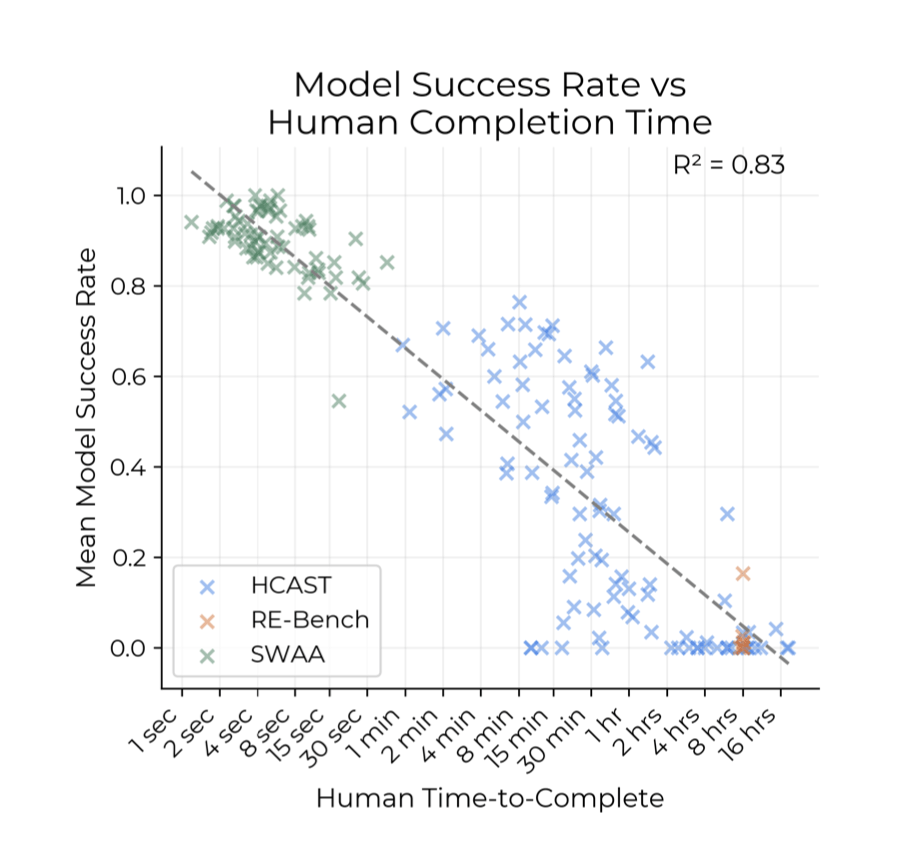
因此,「以人类时间衡量任务难度」,这个指标非常合理。
模型越新,任务越难:能力进化有迹可循
证明了这个指标的有效性,接下来还要看看各个模型在这个指标上的表现。
团队进一步检验了不同模型能完成的任务所对应的人类耗时。
结果相当符合直觉:
2023年之前的模型(如GPT-2和GPT-3)只能完成那些只需写几句话的简单任务。
而对于人类耗时超过1分钟的任务,它们则迅速败下阵来。
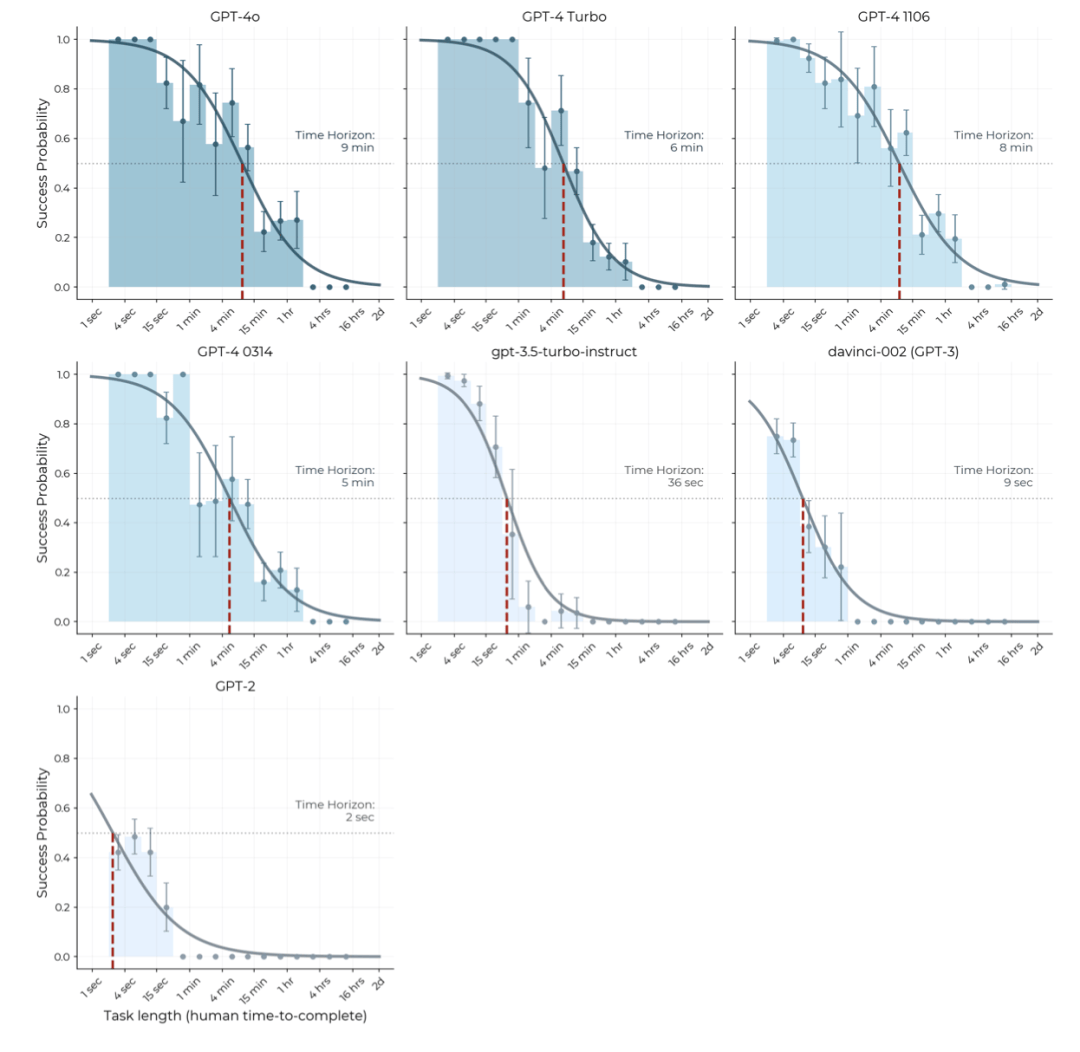
相比之下,最新的前沿模型(如Claude 3.5 Sonnet和o1)则可以完成一些人类要花数小时的任务,甚至在十几小时的超长程任务上还能保持一定的成功率。





