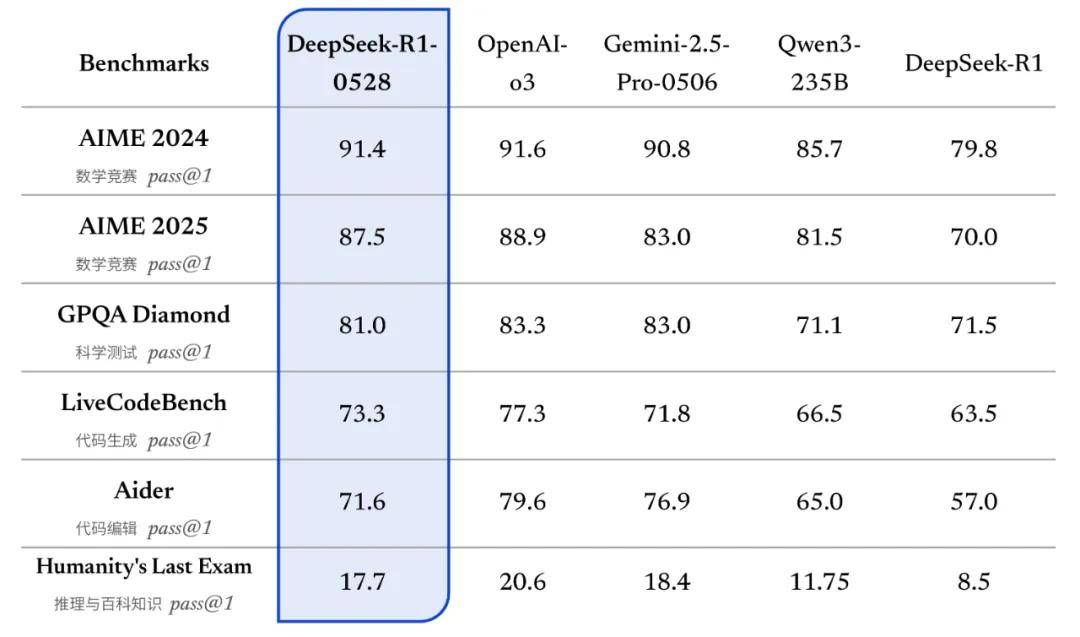
官方公布的测试显示,DeepSeek-R1-0528在数学竞赛、科学、代码生成和编辑,以及推理与百科知识等主流基准上的表现,相较DeepSeek-R1均有明显提升。
DeepSeek提到,相较于旧版R1,新版模型在复杂推理任务中的表现有了显著改进。如在数学测试AIME 2025中,准确率由70%提升至87.5%,这得益于模型在推理过程中的思维深度增强。
在该测试中,旧版模型平均每题使用12K tokens,而新版模型平均每题使用23K tokens,表明其在解题过程中进行了更为详尽和深入的思考。
更为重要的是,DeepSeek-R1-0528在这六大基准测试中均超过阿里的Qwen3-235B,数学和代码生成能力也超过谷歌Gemini-2.5-Pro-0506。但整体来看,该模型与o3相比仍还有微弱差距。
其它更新方面,新版DeepSeek-R1针对幻觉问题进行了优化。此前,在Vectara HHEM人工智能幻觉测试(通过检测语言模型生成内容是否与原始证据一致,从而评估模型的幻觉率)中,DeepSeek-R1幻觉率为14.3%,是DeepSeek-V3的近4倍,也远超行业平均水平。
与旧版相比,此次更新后的模型在改写润色、总结摘要、阅读理解等场景中,幻觉率降低45%-50%左右,能够有效地提供更为准确、可靠的结果。
在创意写作方面,更新后的R1模型针对议论文、小说、散文等文体进行了进一步优化,能够输出篇幅更长、结构内容更完整的长篇作品,同时呈现出更加贴近人类偏好的写作风格。
DeepSeek-R1-0528还支持工具调用(不支持在thinking中进行),其在Tau-Bench测评成绩为Airline 53.5% / Retail 63.9%,与OpenAI-o1-high相当,但与o3-High及Claude 4 Sonnet 仍有差距。
Tau-Bench是OpenAI董事会主席布雷特·泰勒(Bret Taylor)创办的公司Sierra推出的评估AI智能体在复杂现实任务中与用户和工具交互的能力,主要设计了Retail(零售场景)和Airline(航空场景)两个垂直领域的评测。
此外,新版R1 API仍支持查看模型思考过程,同时增加了Function Calling和JsonOutput的支持。Function Calling也就是函数调用,是一种允许AI模型在特定任务中调用预定义函数或API的机制,用于增强模型的处理能力和功能,是大模型与外部世界交互的关键技术。
OpenAI的GPT模型、百度文心模型等主流模型均支持Function Calling。这也意味着,DeepSeek-R1-0528模型将增强与外部工具交互的能力,有助于智能体应用开发。
DeepSeek还表示,DeepSeek-R1-0528在前端代码生成、角色扮演等领域的能力也均有更新和提升。
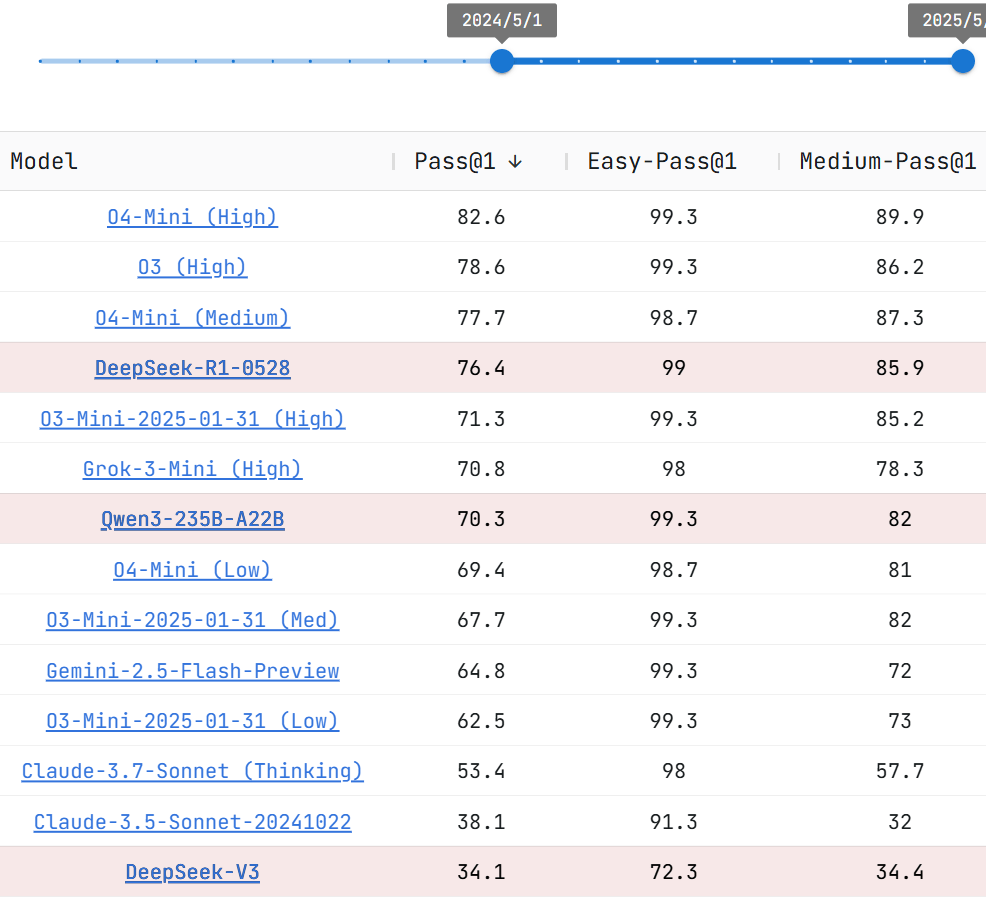
在代码能力方面,代码测试平台Live CodeBench显示,在最近一年内的模型评测中,DeepSeek-R1-0528性能仅次于OpenAI在4月发布的o4 mini和o3-high版本。
在模型上下文长度方面,R1新模型在官方网站、小程序、App端和API中的模型上下文长度仍为64K。如果用户对更长的上下文长度有需求,可以通过其他第三方平台调用上下文长度为128K的开源版本R1-0528模型。





